写在前面 介绍最近看的两篇基于ℓ 1 \ell_1 ℓ 1 , ^, ,
基于ℓ 1 \ell_1 ℓ 1 PCA简介 降维技术 数据可视化 人脸识别(特征脸,eigenface) 广泛应用 PCA优缺点 L2-PCA 传统的主成分分析 L2 PCA的两个目的
min W − tr ( W T X X T W ) s.t. W T W = I \min_W -\text{tr}(W^TXX^TW)\quad \text{s.t.} W^TW = I
W min − tr ( W T X X T W ) s.t. W T W = I
max W tr ( W T X X T W ) s.t. W T W = I \max_W \text{tr}(W^TXX^TW)\quad \text{s.t.} W^TW = I
W max tr ( W T X X T W ) s.t. W T W = I
最小化误差和最大化方差在距离度量取L2-范数时是等价的,并可通过SVD来求解。从第一点看出PCA的本质是保证原样本点和投影重构的样本点距离服从高斯分布,其最小化可以去除高斯噪声
E 2 ( W , V ) = ∥ X − W V ∥ 2 2 = ∑ i = 1 n ∥ x i − ∑ k = 1 m w k v k i ∥ 2 2 = ∑ i = 1 n ∑ j = 1 d ( x j i − ∑ k = 1 m w j k v k i ) 2 \begin{aligned}
E_2(W,V) &= \|X-WV\|_2^2 = \sum_{i=1}^n \|x_i - \sum_{k=1}^m w_k v_{ki}\|_2^2 \\
&= \sum_{i=1}^n \sum_{j=1}^d (x_{ji} - \sum_{k=1}^m w_{jk}v_{ki})^2
\end{aligned} E 2 ( W , V ) = ∥ X − W V ∥ 2 2 = i = 1 ∑ n ∥ x i − k = 1 ∑ m w k v k i ∥ 2 2 = i = 1 ∑ n j = 1 ∑ d ( x j i − k = 1 ∑ m w j k v k i ) 2
假设W W W min V E 2 ( V ) s.t. W T W = I \min_V E_2(V)\quad \text{s.t.} W^TW = I min V E 2 ( V ) s.t. W T W = I V = W T X V=W^T X V = W T X
X = W V ⇔ V = W T W V = W T X X=WV \Leftrightarrow V = W^TWV = W^TX
X = W V ⇔ V = W T W V = W T X
所以就有了如下等价问题
min ∥ X − W V ∥ 2 ⇔ min ∥ X − W W T X ∥ 2 ⟺ min ∥ W T X ∥ 2 \min \|X-WV\|_2 \Leftrightarrow \min \|X-WW^TX\|_2 \iff \min \|W^TX\|_2
min ∥ X − W V ∥ 2 ⇔ min ∥ X − W W T X ∥ 2 ⟺ min ∥ W T X ∥ 2
L2 PCA对异常值和稀疏噪声效果很差,因此原始数据和投影之间的距离用拉普拉斯分布来代替高斯分布,根据极大似然估计提出L1 PCA。
E 1 ( W , V ) = ∥ X − W V ∥ 1 = ∑ i = 1 n ∥ x i − ∑ k = 1 m w k v k i ∥ 1 = ∑ i = 1 n ∑ j = 1 d ∣ x j i − ∑ k = 1 m w j k v k i ∣ \begin{aligned}
E_1(W,V) &= \|X-WV\|_1 = \sum_{i=1}^n \|x_i - \sum_{k=1}^m w_k v_{ki}\|_1 \\
&= \sum_{i=1}^n \sum_{j=1}^d |x_{ji} - \sum_{k=1}^m w_{jk}v_{ki}|
\end{aligned} E 1 ( W , V ) = ∥ X − W V ∥ 1 = i = 1 ∑ n ∥ x i − k = 1 ∑ m w k v k i ∥ 1 = i = 1 ∑ n j = 1 ∑ d ∣ x j i − k = 1 ∑ m w j k v k i ∣
由于L1范数不是旋转不变的,且等距曲面倾斜不利于获取最优的精确解。R1 PCA结合L2 PCA和L1 PCA来保证旋转不变性,但是对维度敏感。
E R 1 ( W , V ) = ∥ X − W V ∥ R 1 = ∑ i = 1 n ( ∑ j = 1 d ( x j i − ∑ k = 1 m w j k v k i ) 2 ) 1 2 E_{R1}(W,V) = \|X-WV\|_{R1} = \sum_{i=1}^n (\sum_{j=1}^d (x_{ji} - \sum_{k=1}^m w_{jk}v_{ki})^2)^{\frac{1}{2}}
E R 1 ( W , V ) = ∥ X − W V ∥ R 1 = i = 1 ∑ n ( j = 1 ∑ d ( x j i − k = 1 ∑ m w j k v k i ) 2 ) 2 1
L1 PCA与R1 PCA的关系更像TV范数的关系:
∥ X i ∥ T V i s o = ∥ ∣ ∇ x X i ∣ 2 + ∣ ∇ y X i ∣ 2 ∥ 1 \quad \left\| X_i \right\|_{\mathrm{TV}}^{\mathrm{iso}} = \left\| \sqrt{\left| \nabla_x X_i \right|^2 + \left|\nabla _y X_i \right|^2 }\right\|_1
∥ X i ∥ T V i s o = ∥ ∥ ∥ ∥ ∥ ∣ ∇ x X i ∣ 2 + ∣ ∇ y X i ∣ 2 ∥ ∥ ∥ ∥ ∥ 1
∥ X i ∥ T V a n i = ∥ ∇ x X i ∥ 1 + ∥ ∇ y X i ∥ 1 \left\| X_i \right\|_{\mathrm{TV}}^{\mathrm{ani}} = \left\| \nabla_x X_i \right\|_1 + \left\|\nabla _y X_i\right\|_1
∥ X i ∥ T V a n i = ∥ ∇ x X i ∥ 1 + ∥ ∇ y X i ∥ 1
回到基于误差的子空间投影优化问题,其解可以通过对偶问题的SVD得到
W ∗ = arg max W ∥ W T X X T W ∥ 2 = arg max W ∥ W T X ∥ 2 s.t. W T W = I W^*=\arg\max_W\|W^TXX^TW\|_2 = \arg\max_W\|W^TX\|_2 \quad \text{s.t.} W^TW = I
W ∗ = arg W max ∥ W T X X T W ∥ 2 = arg W max ∥ W T X ∥ 2 s.t. W T W = I
注意,上式可解释为投影点W T X W^TX W T X
图片来源
L1-PCA 文献从方差角度考虑,用特征空间的最大化L1-范数方差来代替最大化基于L2-范数方差,以实现鲁棒和旋转不变的PCA。求解算法简单有效,且可证明达到局部最大解。具体优化模型PCA-L1如下:
W ∗ = arg max W ∥ W T X ∥ 1 = arg max W ∑ i = 1 n ∑ k = 1 m ∣ ∑ j = 1 d w j k x j i ∣ s.t. W T W = I W^* = \arg\max_W\|W^TX\|_1 = \arg\max_W \sum_{i=1}^n \sum_{k=1}^m | \sum_{j=1}^d w_{jk}x_{ji}| \quad \text{s.t.} W^TW = I
W ∗ = arg W max ∥ W T X ∥ 1 = arg W max i = 1 ∑ n k = 1 ∑ m ∣ j = 1 ∑ d w j k x j i ∣ s.t. W T W = I
PCA-L1模型比L1-PCA具备旋转不变性,比L2-PCA具备异常值的鲁棒性。该问题可以通过简化为m m m
w ∗ = arg max w ∥ w T X ∥ 1 = arg max w ∑ i = 1 n ∣ w T x i ∣ s.t. ∥ w ∥ 2 = I w^* = \arg\max_w\|w^TX\|_1 = \arg\max_w \sum_{i=1}^n |w^Tx_i| \quad \text{s.t.} \|w\|_2 = I
w ∗ = arg w max ∥ w T X ∥ 1 = arg w max i = 1 ∑ n ∣ w T x i ∣ s.t. ∥ w ∥ 2 = I
初始化 :任取w ( 0 ) w(0) w ( 0 ) w ( 0 ) ← w ( 0 ) / ∥ w ( 0 ) ∥ 2 w(0)\leftarrow w(0)/\|w(0)\|_2 w ( 0 ) ← w ( 0 ) / ∥ w ( 0 ) ∥ 2 t = 0 t=0 t = 0 极性检查 :若w T ( t ) x i < 0 w^T(t)x_i<0 w T ( t ) x i < 0 p i ( t ) = − 1 p_i(t) = -1 p i ( t ) = − 1 p i ( t ) = 1 p_i(t) = 1 p i ( t ) = 1 翻转和最大化 :t ← t + 1 t\leftarrow t+1 t ← t + 1 w ( t ) = ∑ i = 1 n p i ( t − 1 ) x i w(t)=\sum_{i=1}^np_i(t-1)x_i w ( t ) = ∑ i = 1 n p i ( t − 1 ) x i w ( t ) ← w ( t ) / ∥ w ( t ) ∥ 2 w(t)\leftarrow w(t)/\|w(t)\|_2 w ( t ) ← w ( t ) / ∥ w ( t ) ∥ 2 判断收敛 :若w ( t ) ≠ w ( t − 1 ) w(t) \neq w(t-1) w ( t ) = w ( t − 1 ) ( 2 ) (2) ( 2 ) 若存在i i i w T ( t ) x i = 0 w^T(t)x_i=0 w T ( t ) x i = 0 w ( t ) ← ( w ( t ) + Δ w ) / ∥ w ( t ) + Δ w ∥ 2 w(t)\leftarrow (w(t)+\Delta w)/\|w(t)+\Delta w\|_2 w ( t ) ← ( w ( t ) + Δ w ) / ∥ w ( t ) + Δ w ∥ 2 ( 2 ) (2) ( 2 ) Δ w \Delta w Δ w 否则w ∗ = w ( t ) w^* = w(t) w ∗ = w ( t ) 迭代过程中
∑ i = 1 n ∣ w T ( t ) x i ∣ = w T ( t ) ( ∑ i = 1 n p i ( t ) x i ) ≥ w T ( t ) ( ∑ i = 1 n p i ( t − 1 ) x i ) ≥ w T ( t − 1 ) ( ∑ i = 1 n p i ( t − 1 ) x i ) = ∑ i = 1 n ∣ w T ( t − 1 ) x i ∣ \begin{aligned}
\sum_{i=1}^n |w^T(t) x_i| &= w^T(t)(\sum_{i=1}^n p_i(t) x_i) \\
& \geq w^T(t)(\sum_{i=1}^n p_i(t-1) x_i)\\
& \geq w^T(t-1)(\sum_{i=1}^n p_i(t-1) x_i)\\
& =\sum_{i=1}^n |w^T(t-1) x_i|
\end{aligned} i = 1 ∑ n ∣ w T ( t ) x i ∣ = w T ( t ) ( i = 1 ∑ n p i ( t ) x i ) ≥ w T ( t ) ( i = 1 ∑ n p i ( t − 1 ) x i ) ≥ w T ( t − 1 ) ( i = 1 ∑ n p i ( t − 1 ) x i ) = i = 1 ∑ n ∣ w T ( t − 1 ) x i ∣
第一个不等号是因为p i ( t ) p_i(t) p i ( t ) w ( t ) w(t) w ( t ) p i ( t ) w T ( t ) x i ≥ 0 p_i(t)w^T(t)x_i\geq0 p i ( t ) w T ( t ) x i ≥ 0 p i ( t − 1 ) p_i(t-1) p i ( t − 1 )
第二个不等号是因为∥ w ( t ) ∥ 2 = ∥ w ( t − 1 ) ∥ 2 \|w(t)\|_2=\|w(t-1)\|_2 ∥ w ( t ) ∥ 2 = ∥ w ( t − 1 ) ∥ 2 ∑ i = 1 n p i ( t − 1 ) x i \sum_{i=1}^n p_i(t-1) x_i ∑ i = 1 n p i ( t − 1 ) x i
∑ i = 1 n p i ( t − 1 ) x i ∥ ∑ i = 1 n p i ( t − 1 ) x i ∥ \frac{\sum_{i=1}^np_i(t-1)x_i}{\|\sum_{i=1}^np_i(t-1)x_i\|}
∥ ∑ i = 1 n p i ( t − 1 ) x i ∥ ∑ i = 1 n p i ( t − 1 ) x i
因此在这一个算法下目标函数是非减的。经过有限步以后可收敛到投影向量w ∗ w^* w ∗ w ∗ w^* w ∗
算法计算复杂度为O ( n d ) × n i t {\mathcal{O}}(nd)\times n_{it} O ( n d ) × n i t d d d n n n
注意,算法寻找的局部最大值并不一定是全局最大值,因此合适的初始值w ( 0 ) w(0) w ( 0 )
回到第三步,投影向量是数据点x i x_i x i w ( t ) ∝ p i ( t − 1 ) x i w(t)\propto p_i(t-1)x_i w ( t ) ∝ p i ( t − 1 ) x i
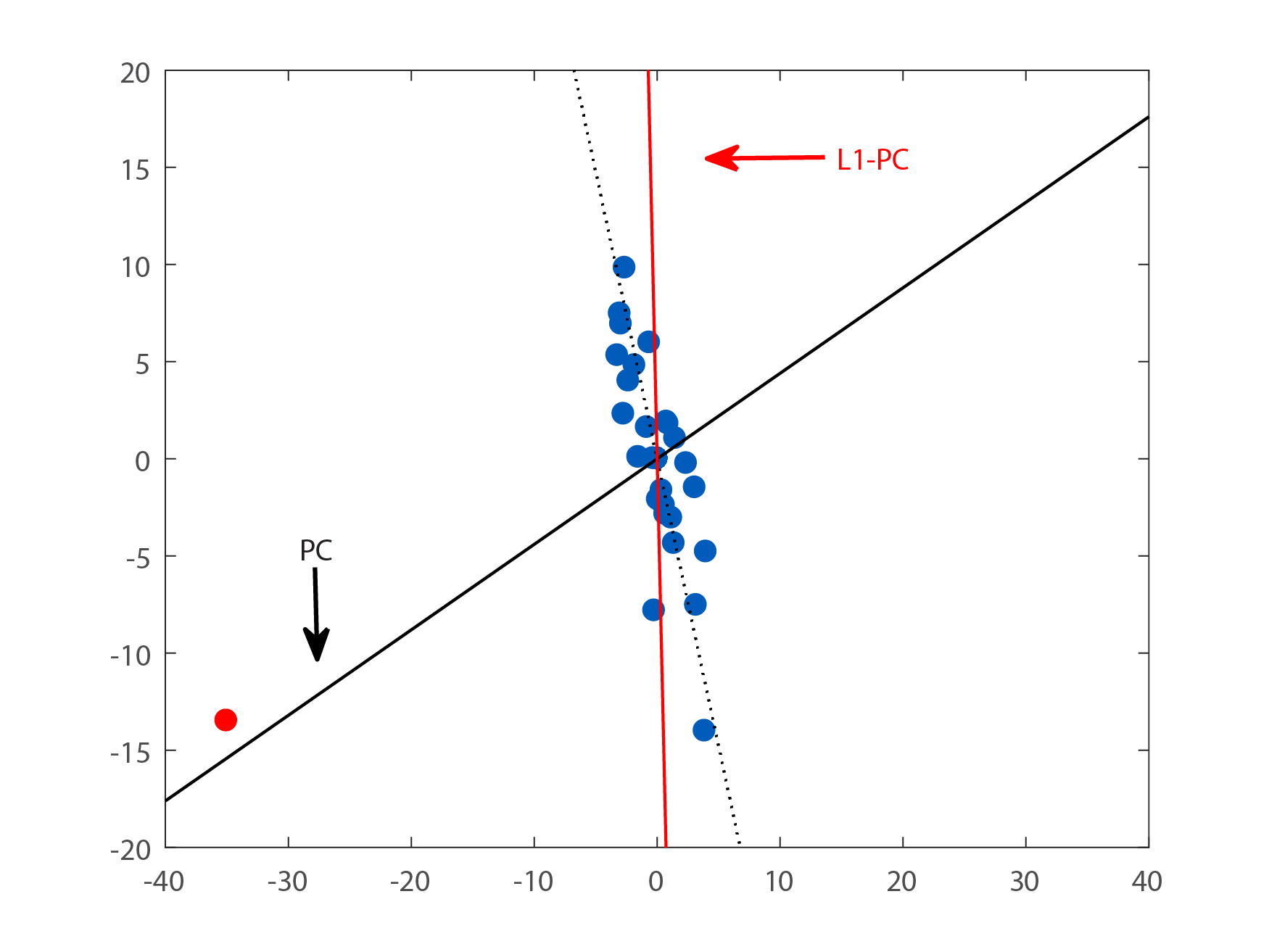
值得注意的是,L1-PCA和L2-PCA算法所得到得子空间非常接近。
上面仅考虑了当m = 1 m=1 m = 1 m > 1 m>1 m > 1
投影向量的正交性由以下三点保证:
w j w_j w j X j X^j X j X j X^j X j
w j − 1 T X j = w j − 1 T X j − 1 − w j − 1 T w j − 1 w j − 1 T X j − 1 = 0 w_{j-1}^T X^j = w_{j-1}^T X^{j-1} - w_{j-1}^T w_{j-1} w_{j-1}^T X^{j-1} = 0
w j − 1 T X j = w j − 1 T X j − 1 − w j − 1 T w j − 1 w j − 1 T X j − 1 = 0
w j − 1 w_{j-1} w j − 1 X j X^j X j w j w_j w j w j − 1 w_{j-1} w j − 1
PCA-L1小结 寻找在投影空间中最大化L1范数的投影。 被证明可找到一个局部最大值。 对异常值具有鲁棒性。 简单且易于实现。 迭代次数较少,相对较快。 迭代次数不取决于输入空间的大小。 相同的技术可以应用于其他特征提取算法 二值核范数最大化问题 对任意矩阵A A A Φ ( A ) \Phi(A) Φ ( A ) A A A
Φ ( A ) = arg min W ∥ A − W ∥ F , s.t. W T W = I n \Phi(A) = \arg\min_{W}\|A-W\|_F,\quad \text{s.t.} W^T W = I_n
Φ ( A ) = arg W min ∥ A − W ∥ F , s.t. W T W = I n
若A = U A Σ A V A T A=U_A \Sigma_A V_A^T A = U A Σ A V A T Φ ( A ) = U A V A T \Phi(A) = U_A V_A^T Φ ( A ) = U A V A T B BNM ∗ B_{\text{BNM}}^* B BNM ∗ 二值核范数最大化问题 (binary nuclear-norm maximization, BNM)的精确解
max B ∈ { ± 1 } N × K ∥ X B ∥ ∗ 2 \max_{B \in \{\pm 1\}^{N \times K}} \|XB\|_*^2
B ∈ { ± 1 } N × K max ∥ X B ∥ ∗ 2
则L1-PCA问题
arg max W ∥ W T X ∥ 1 s.t. W T W = I \arg\max_W\|W^TX\|_1 \quad \text{s.t.} W^TW = I
arg W max ∥ W T X ∥ 1 s.t. W T W = I
的精确解为W ℓ 1 ∗ = Φ ( X B BNM ∗ ) W_{\ell_1}^* = \Phi(XB_{\text{BNM}}^*) W ℓ 1 ∗ = Φ ( X B BNM ∗ ) B BNM ∗ = s g n ( X T W ℓ 1 ∗ ) B_{\text{BNM}}^* = \mathbf{sgn}(X^T W_{\ell_1}^*) B BNM ∗ = s g n ( X T W ℓ 1 ∗ )
∥ X T W ℓ 1 ∗ ∥ 1 = ∥ X B BNM ∗ ∥ ∗ \|X^T W_{\ell_1}^*\|_1 = \|XB_{\text{BNM}}^*\|_*
∥ X T W ℓ 1 ∗ ∥ 1 = ∥ X B BNM ∗ ∥ ∗
算法 L1-PCA模型可通过以下两步法来解决
求解二值核范数最大化问题来获得B BNM ∗ B_{\text{BNM}}^* B BNM ∗ 通过对X B BNM ∗ XB_{\text{BNM}}^* X B BNM ∗ W ℓ 1 ∗ W_{\ell_1}^* W ℓ 1 ∗ 其中第一步可通过L1-BF算法解决
基于ℓ 1 \ell_1 ℓ 1 上面提到L1-PCA模型得实值优化问题如下:
Q l 1 ∗ = arg max Q ∈ R D × K ∥ Q T X ∥ 1 s.t. Q T Q = I k Q_{l_1}^* = \arg\max_{Q \in \mathbb{R}^{D\times K}}\|Q^T X\|_1 \quad \text{s.t.} Q^T Q = I_k
Q l 1 ∗ = arg Q ∈ R D × K max ∥ Q T X ∥ 1 s.t. Q T Q = I k
对应的复值版本则为
Q l 1 ∗ = arg max Q ∈ C D × K ∥ Q H X ∥ 1 s.t. Q H Q = I k Q_{l_1}^* = \arg\max_{Q \in \mathbb{C}^{D\times K}}\|Q^H X\|_1 \quad \text{s.t.} Q^H Q = I_k
Q l 1 ∗ = arg Q ∈ C D × K max ∥ Q H X ∥ 1 s.t. Q H Q = I k
该问题是一个NP-hard问题,目前研究集中于近似求解或求次优解。文献给出一个很巧妙的算法。
复数方向s g n \mathbf{sgn} s g n 任意复数可表示为模长和角度乘积,其中角度表示为
s g n ( a ) = e j A r g ( a ) = t a n − 1 ( ℑ { a } ℜ { a } ) = a ∣ a ∣ = arg max b ∈ U ∣ b − a ∣ = arg max b ∈ U ℜ { b H a } \begin{aligned}
\mathbf{sgn}(a) &= e^{j \mathbf{Arg}(a)} = tan^{-1}(\frac{\Im\{a\}}{\Re\{a\}}) = \frac{a}{|a|} \\
&= \arg\max_{b \in U} |b-a|= \arg\max_{b \in U} \Re\{b^H a\}
\end{aligned} s g n ( a ) = e j A r g ( a ) = t a n − 1 ( ℜ { a } ℑ { a } ) = ∣ a ∣ a = arg b ∈ U max ∣ b − a ∣ = arg b ∈ U max ℜ { b H a }
矩阵的形式如下
s g n ( A ) = [ sgn ( a 1 , 1 ) ⋯ sgn ( a 1 , n ) ⋮ ⋱ ⋮ sgn ( a m , 1 ) ⋯ sgn ( a m , n ) ] = arg max B ∈ U n × m ℜ { B A } \mathbf{sgn}(A) =
\left[\begin{array}{ccc}
\text{sgn}\left(a_{1,1}\right) & \cdots & \text{sgn}\left(a_{1, n}\right) \\
\vdots & \ddots & \vdots \\
\text{sgn}\left(a_{m, 1}\right) & \cdots & \text{sgn}\left(a_{m, n}\right)
\end{array}\right]
= \arg\max_{B \in U^{n \times m}} \Re\{BA\} s g n ( A ) = ⎣ ⎢ ⎢ ⎡ sgn ( a 1 , 1 ) ⋮ sgn ( a m , 1 ) ⋯ ⋱ ⋯ sgn ( a 1 , n ) ⋮ sgn ( a m , n ) ⎦ ⎥ ⎥ ⎤ = arg B ∈ U n × m max ℜ { B A }
对应的最优值为矩阵的ℓ 1 \ell_1 ℓ 1
∥ A ∥ 1 = max B ∈ U n × m ℜ { B A } = t r ( s g n ( A ) H A ) \|A\|_1 = \max_{B \in U^{n \times m}} \Re\{BA\} = tr(\mathbf{sgn}(A)^H A)
∥ A ∥ 1 = B ∈ U n × m max ℜ { B A } = t r ( s g n ( A ) H A )
而核范数作为奇异值之和,也可表示为
∥ A ∥ ∗ = max Q ∈ C m × n ℜ { t r ( Q H A ) } s.t. Q H Q = I n \|A\|_* = \max_{Q \in \mathbb{C}^{m\times n}}\Re\{ tr(Q^H A)\} \quad \text{s.t.} Q^H Q = I_n
∥ A ∥ ∗ = Q ∈ C m × n max ℜ { t r ( Q H A ) } s.t. Q H Q = I n
记上式最大化的酉矩阵u n t ( A ) = U V H \mathbf{unt}(A) = UV^H u n t ( A ) = U V H A A A
A = u n t ( A ) ( A H A ) 1 2 A = \mathbf{unt}(A)(A^H A)^{\frac{1}{2}}
A = u n t ( A ) ( A H A ) 2 1
单位模优化(重点 ) max Q ∈ C D × K ∥ Q H X ∥ 1 = max Q ∈ C D × K t r ( s g n ( Q H X ) H Q H X ) = max Q ∈ C D × K B ∈ U N × K ℜ { t r ( B Q H X ) } = max B ∈ U N × K ∥ X B ∥ ∗ \begin{aligned}
\max_{Q \in \mathbb{C}^{D\times K}}\|Q^H X\|_1 &= \max_{Q \in \mathbb{C}^{D\times K}} tr(\mathbf{sgn}(Q^H X)^H Q^H X) \\
&= \max_{Q \in \mathbb{C}^{D\times K} B\in U^{N\times K}} \Re\{ tr(B Q^H X)\} \\
&= \max_{B\in U^{N\times K}}\|XB\|_*
\end{aligned} Q ∈ C D × K max ∥ Q H X ∥ 1 = Q ∈ C D × K max t r ( s g n ( Q H X ) H Q H X ) = Q ∈ C D × K B ∈ U N × K max ℜ { t r ( B Q H X ) } = B ∈ U N × K max ∥ X B ∥ ∗
最优解对( Q ℓ 1 ∗ , B ∗ ) (Q_{\ell_1}^*,B^*) ( Q ℓ 1 ∗ , B ∗ )
Q ℓ 1 ∗ = u n t ( X B ∗ ) = u n t ( X s g n ( X H Q ℓ 1 ∗ ) ) B ∗ = s g n ( X H Q ℓ 1 ∗ ) = s g n ( X H u n t ( X B ∗ ) ) \begin{aligned}
Q_{\ell_1}^*&=\mathbf{unt}(XB^*)=\mathbf{unt}(X\mathbf{sgn}(X^H Q_{\ell_1}^*))\\
B^* &= \mathbf{sgn}(X^H Q_{\ell_1}^*)= \mathbf{sgn}(X^H \mathbf{unt}(XB^*))
\end{aligned} Q ℓ 1 ∗ B ∗ = u n t ( X B ∗ ) = u n t ( X s g n ( X H Q ℓ 1 ∗ ) ) = s g n ( X H Q ℓ 1 ∗ ) = s g n ( X H u n t ( X B ∗ ) )
case 低秩矩阵 当r a n k ( X ) < D rank(X)<D r a n k ( X ) < D X = U r S r V r H X=U_r S_r V_r^H X = U r S r V r H
∥ X B ∥ ∗ = ∥ U r S r V r H B ∥ ∗ = t r ( ( U r S r V r H B ) H ( U r S r V r H B ) 1 2 ) = t r ( ( B H V r H S r H S r V r H B ) 1 2 ) = ∥ S r V r H B ∥ ∗ \begin{aligned}
\|XB\|_* &= \|U_r S_r V_r^H B\|_* = tr((U_r S_r V_r^H B)^H(U_r S_r V_r^H B)^{\frac{1}{2}})\\
&= tr((B^H V_r^H S_r^H S_r V_r^H B)^{\frac{1}{2}}) = \|S_r V_r^H B\|_*
\end{aligned} ∥ X B ∥ ∗ = ∥ U r S r V r H B ∥ ∗ = t r ( ( U r S r V r H B ) H ( U r S r V r H B ) 2 1 ) = t r ( ( B H V r H S r H S r V r H B ) 2 1 ) = ∥ S r V r H B ∥ ∗
记Y = S r V r H Y = S_r V_r^H Y = S r V r H Q ^ ℓ 1 ∗ = arg min Q ∈ C r × K ∥ Q H H ∥ 1 s.t. Q H Q = I k \hat Q _{\ell_1}^* = \arg\min_{Q \in \mathbb{C}^{r\times K}} \|Q^HH\|_1 \quad \text{s.t.} Q^H Q = I_k Q ^ ℓ 1 ∗ = arg min Q ∈ C r × K ∥ Q H H ∥ 1 s.t. Q H Q = I k
U r Y B ∗ = U r u n t ( Y B ∗ ) ⋅ ( B H V r H S r H S r V r H B ) 1 2 = X B ∗ = u n t ( X B ∗ ) ⋅ ( B H V r H S r H S r V r H B ) 1 2 \begin{aligned}
U_r Y B^* = U_r \mathbf{unt}(YB^*) \cdot (B^H V_r^H S_r^H S_r V_r^H B)^{\frac{1}{2}} \\
= XB^* = \mathbf{unt}(XB^*) \cdot (B^H V_r^H S_r^H S_r V_r^H B)^{\frac{1}{2}}
\end{aligned} U r Y B ∗ = U r u n t ( Y B ∗ ) ⋅ ( B H V r H S r H S r V r H B ) 2 1 = X B ∗ = u n t ( X B ∗ ) ⋅ ( B H V r H S r H S r V r H B ) 2 1
u n t ( X B ∗ ) = U r u n t ( Y B ∗ ) \mathbf{unt}(XB^*) = U_r \mathbf{unt}(YB^*)
u n t ( X B ∗ ) = U r u n t ( Y B ∗ )
Q ℓ 1 ∗ = U r Q ^ ℓ 1 ∗ Q _{\ell_1}^* = U_r \hat Q _{\ell_1}^*
Q ℓ 1 ∗ = U r Q ^ ℓ 1 ∗
∥ ( Q ℓ 1 ∗ ) H X ∥ 1 = ∥ X B ∗ ∥ 1 = ∥ Y B ∗ ∥ 1 = ∥ ( Q ℓ 1 ∗ ) H Y ∥ 1 \|(Q _{\ell_1}^*)^H X\|_1 = \|XB^*\|_1 = \|YB^*\|_1 = \|(Q _{\ell_1}^*)^H Y\|_1
∥ ( Q ℓ 1 ∗ ) H X ∥ 1 = ∥ X B ∗ ∥ 1 = ∥ Y B ∗ ∥ 1 = ∥ ( Q ℓ 1 ∗ ) H Y ∥ 1
case 单成分 max q ∈ C D × 1 , ∥ q ∥ 2 = 1 ∥ q H X ∥ 1 = max b ∈ U N × 1 ∥ X b ∥ ∗ = max b ∈ U N × 1 ∥ X b ∥ 2 = max b ∈ U N × 1 ( b H X H X b ) 1 2 \begin{aligned}
\max_{q \in \mathbb{C}^{D\times 1},\|q\|_2 = 1} \|q^H X\|_1 & = \max_{b \in U^{N \times 1}} \|Xb\|_*= \max_{b \in U^{N \times 1}} \|Xb\|_2\\
& = \max_{b \in U^{N \times 1}} (b^H X^H X b)^{\frac{1}{2}}
\end{aligned} q ∈ C D × 1 , ∥ q ∥ 2 = 1 max ∥ q H X ∥ 1 = b ∈ U N × 1 max ∥ X b ∥ ∗ = b ∈ U N × 1 max ∥ X b ∥ 2 = b ∈ U N × 1 max ( b H X H X b ) 2 1
该单位模二次优化问题的解
q ℓ 1 ∗ = u n t ( X b ∗ ) = X b ∗ ∥ X b ∗ ∥ 2 − 1 q_{\ell_1}^* = \mathbf{unt}(Xb^*) = Xb^*\|Xb^*\|_2^{-1}
q ℓ 1 ∗ = u n t ( X b ∗ ) = X b ∗ ∥ X b ∗ ∥ 2 − 1
b ∗ = s g n ( X H q ℓ 1 ∗ ) = s g n ( X H u n t ( X b ∗ ) ) = s g n ( X H X b ∗ ) b^* = \mathbf{sgn}(X^H q_{\ell_1}^*) = \mathbf{sgn}(X^H \mathbf{unt}(Xb^*)) =\mathbf{sgn}(X^H Xb^*)
b ∗ = s g n ( X H q ℓ 1 ∗ ) = s g n ( X H u n t ( X b ∗ ) ) = s g n ( X H X b ∗ )
因为s g n ( X H X b ∗ ) \mathbf{sgn}(X^H Xb^*) s g n ( X H X b ∗ ) ∥ X b ∥ 2 \|Xb\|_2 ∥ X b ∥ 2
记ω ( b ) = b ˉ ⊙ ( X H X b ) \omega(b) = \bar b \odot (X^H X b) ω ( b ) = b ˉ ⊙ ( X H X b ) b b b
∥ x n ∥ 2 2 ≤ ω n ( b ) ∈ R ∀ n ∈ { 1 , ⋯ , N } \|x_n\|_2^2 \leq \omega_n(b) \in \mathbb R \quad \forall n \in \{1,\cdots, N\}
∥ x n ∥ 2 2 ≤ ω n ( b ) ∈ R ∀ n ∈ { 1 , ⋯ , N }
不等式引导符号函数的对应结果为
b = s g n ( ( X H X − d i a g ( ∥ x 1 ∥ 2 2 , ⋯ , ∥ x N ∥ 2 2 ) ) b ) b = \mathbf{sgn}((X^H X- \mathbf{diag}(\|x_1\|_2^2,\cdots,\|x_N\|_2^2)) b)
b = s g n ( ( X H X − d i a g ( ∥ x 1 ∥ 2 2 , ⋯ , ∥ x N ∥ 2 2 ) ) b )
s g n ( X H X b ∗ ) \mathbf{sgn}(X^H Xb^*) s g n ( X H X b ∗ ) ω ( ⋅ ) \omega(\cdot) ω ( ⋅ ) ω n ( b ∗ ) > 0 \omega_n(b^*)>0 ω n ( b ∗ ) > 0 ω n ( b ∗ ) ≥ ∥ x n ∥ 2 2 > 0 \omega_n(b^*)\geq\|x_n\|_2^2>0 ω n ( b ∗ ) ≥ ∥ x n ∥ 2 2 > 0
复L1-PCA算法 B ( i ) = s g n ( X H u n t ( X B ( i − 1 ) ) ) B^{(i)}= \mathbf{sgn}(X^H \mathbf{unt}(X B^{(i-1)}))
B ( i ) = s g n ( X H u n t ( X B ( i − 1 ) ) )
收敛性
∥ X B ( i ) ∥ ∗ = max Q ℜ { t r ( Q H X B ( i ) ) } ≥ ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X B ( i ) } = ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X s g n ( X H u n t ( X B ( i − 1 ) ) ) } = max B ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X B ′ } ≥ ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X B ( i − 1 ) } = ∥ X B ( i − 1 ) ∥ ∗ \begin{aligned}
\|X B^{(i)}\|_* & = \max_Q \Re\{ tr(Q^H XB^{(i)})\} \\
& \geq \Re\{ tr(\mathbf{unt}(XB^{(i-1)}))^H XB^{(i)}\}\\
& = \Re\{ tr(\mathbf{unt}(XB^{(i-1)}))^H X \mathbf{sgn}(X^H \mathbf{unt}(X B^{(i-1)}))\}\\
& = \max_B \Re\{ tr(\mathbf{unt}(XB^{(i-1)}))^H X B'\}\\
& \geq \Re\{ tr(\mathbf{unt}(XB^{(i-1)}))^H X B^{(i-1)}\} = \|X B^{(i-1)}\|_*
\end{aligned} ∥ X B ( i ) ∥ ∗ = Q max ℜ { t r ( Q H X B ( i ) ) } ≥ ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X B ( i ) } = ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X s g n ( X H u n t ( X B ( i − 1 ) ) ) } = B max ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X B ′ } ≥ ℜ { t r ( u n t ( X B ( i − 1 ) ) ) H X B ( i − 1 ) } = ∥ X B ( i − 1 ) ∥ ∗
b ( i ) = s g n ( ( X H X − d i a g ( ∥ x 1 ∥ 2 2 , ⋯ , ∥ x N ∥ 2 2 ) ) b ( i − 1 ) ) b^{(i)} = \mathbf{sgn}((X^H X- \mathbf{diag}(\|x_1\|_2^2,\cdots,\|x_N\|_2^2)) b^{(i-1)})
b ( i ) = s g n ( ( X H X − d i a g ( ∥ x 1 ∥ 2 2 , ⋯ , ∥ x N ∥ 2 2 ) ) b ( i − 1 ) )
收敛性
∥ A d b ( i ) ∥ 1 = max b ∈ U N × 1 ℜ { b H A d b ( i ) } ≥ ℜ { b ( i − 1 ) H A d b ( i ) } = ℜ { b ( i − 1 ) H A d sgn ( A d b ( i − 1 ) ) } = ∥ A d b ( i − 1 ) ∥ 1 \begin{aligned}
\left\|\mathbf{A}_{d} \mathbf{b}^{(i)}\right\|_{1} &=\max _{\mathbf{b} \in U^{N \times 1}} \Re\left\{\mathbf{b}^{H} \mathbf{A}_{d} \mathbf{b}^{(i)}\right\} \\
& \geq \Re\left\{\mathbf{b}^{(i-1)^{H}} \mathbf{A}_{d} \mathbf{b}^{(i)}\right\} \\
&=\Re\left\{\mathbf{b}^{(i-1)^{H}} \mathbf{A}_{d} \text{sgn}\left(\mathbf{A}_{d} \mathbf{b}^{(i-1)}\right)\right\} \\
&=\left\|\mathbf{A}_{d} \mathbf{b}^{(i-1)}\right\|_{1}
\end{aligned} ∥ ∥ ∥ ∥ A d b ( i ) ∥ ∥ ∥ ∥ 1 = b ∈ U N × 1 max ℜ { b H A d b ( i ) } ≥ ℜ { b ( i − 1 ) H A d b ( i ) } = ℜ { b ( i − 1 ) H A d sgn ( A d b ( i − 1 ) ) } = ∥ ∥ ∥ ∥ A d b ( i − 1 ) ∥ ∥ ∥ ∥ 1
总结 改变传统问题的范数是一直研究思路,第一篇文章将PCA的ℓ 2 \ell_2 ℓ 2 ℓ 1 \ell_1 ℓ 1 ℓ 1 \ell_1 ℓ 1
max Q ∈ C D × K ∥ Q H X ∥ 1 = max B ∈ U N × K ∥ X B ∥ ∗ \max_{Q \in \mathbb{C}^{D\times K}}\|Q^H X\|_1 = \max_{B\in U^{N\times K}}\|XB\|_*
Q ∈ C D × K max ∥ Q H X ∥ 1 = B ∈ U N × K max ∥ X B ∥ ∗
将原问题改为单模优化问题。
参考文献