写在前面
介绍最近看的基于ℓp范数主成分分析(Principal Component Analysis, PCA)的文章
基于ℓp范数的主成分分析
F2(W)=21i=1∑N∥WTxi∥22=21tr(WTXXTW)
F1(W)=i=1∑N∥WTxi∥1=i=1∑Nj=1∑m∣wjTxi∣
Fp(W)=p1i=1∑N∥WTxi∥pp=p1i=1∑Nj=1∑m∣wjTxi∣p
求解算法(m=1)
梯度下降
对应模型
w∗=argwminFp(w)=argwminp1i=1∑N∣wTxi∣ps.t.wTw=1
记ai=wTxi,则 Fp(w)=p1∑i=1N(sgn(ai)ai)p对w的梯度为
∇w=dwdFp(w)=i=1∑NdaidFp(w)dwdai=i=1∑N[sgn(ai)ai]p−1[sgn′(ai)ai+sgn(ai)]xi=i=1∑Nsgn′(ai)sgnp−1(ai)aipxi+i=1∑Nsgnp(ai)aip−1xi=2i=1∑Nδ(ai)sgnp−1(ai)aipxi+i=1∑Nsgn(ai)∣ai∣p−1xi
当ai=wTxi=0,则梯度的第一项为0,即
∇w=i=1∑Nsgn(wTxi)∣∣∣wTxi∣∣∣p−1xi
若p>1,即使存在奇异点(wTxi=0),第一项也为0,其梯度也是良定义的(见上式)。而当p<1时需要对w进行扰动来避免奇异情况(wTxi=0)。
该问题可以通过最速下降法来迭代求解。
- 初值选取
- ℓ2-PCA的结果
- 具有最大范数的样本方向
- 学习率控制收敛速率,α=N0.1
- step 2 避免当p≤1时的奇异情况
- step 5 保证规范化∥w∥2=1

基于梯度下降的PCA-Lp算法
梯度正交向量
∇w⊥=∇w−w(wT∇w)=(Id−wwT)∇w=(Id−wwT)i=1∑Nsgn(wTxi)∣∣∣wTxi∣∣∣p−1xi
令
ci=sgn(wTxi)∣∣∣wTxi∣∣∣p−1,vi=(Id−wwT)xi,fi=civi
则
∇w⊥=i=1∑Ncivi=i=1∑Nfi
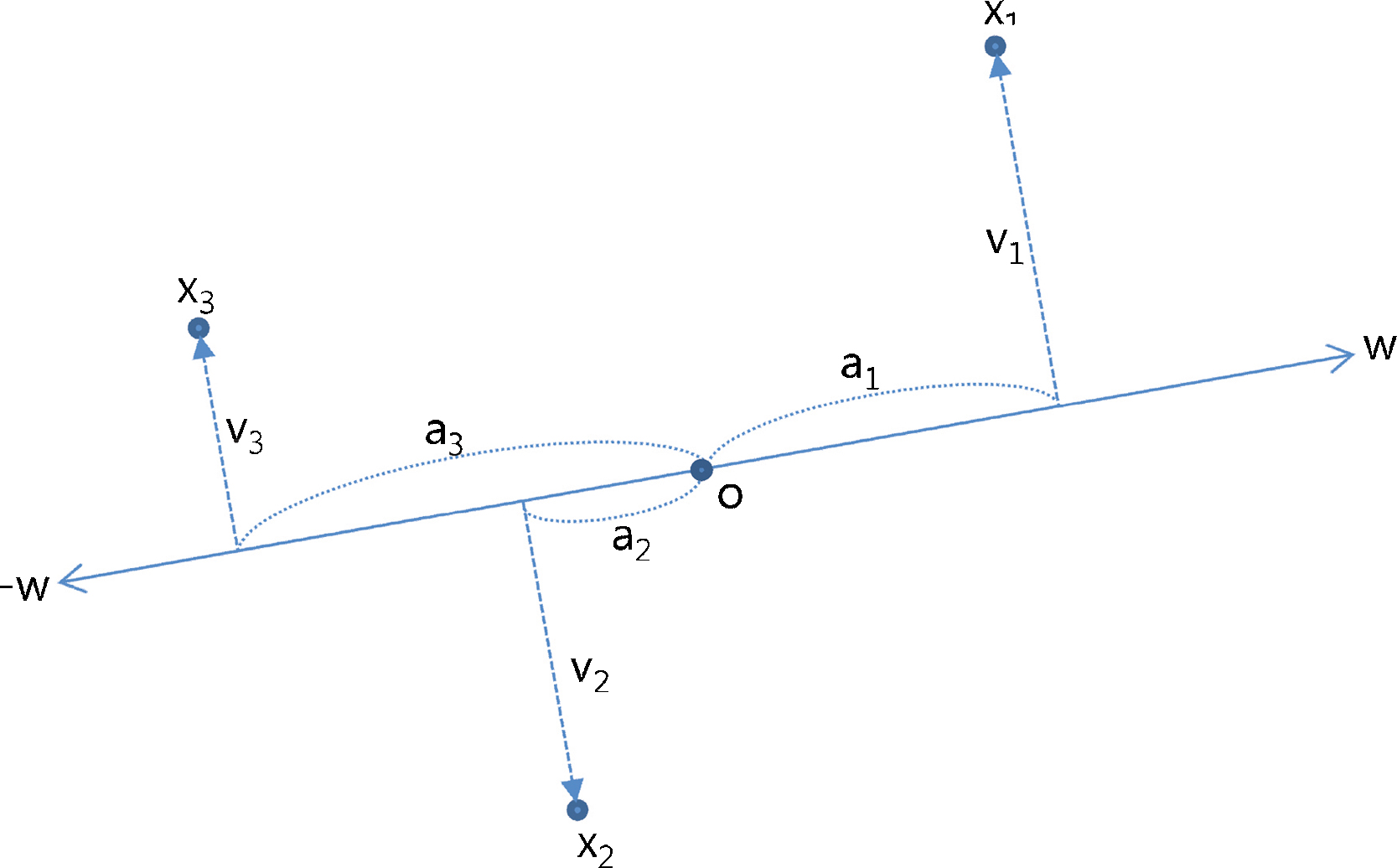
- ai=∣wTxi∣,vi=xi−w(wTxi)
- w过原点O旋转
- 每一个样本 xi 对 w 施加一个正交的力 fi
- 当 wTxi>0 ,点 xi 对 w 产生拉力
- 当 wTxi<0 ,点 xi 对 w 产生推力,反之对 −w 产生拉力
- 力的大小为∣fi∣=aip−1∣vi∣
- p=2时,∣fi∣=ai∣vi∣,力收到两方面的乘积影响(拟合性)
- p=1时,∣fi∣=∣vi∣,力只收到一方面的乘积影响(鲁棒性)
- p<1时,∣fi∣=(ai∣vi∣)1−p∣vi∣p,ai对力产生负影响,从而降低异常值的干扰
- p→0时,∣fi∣=ai∣vi∣
传统PCA联系
当p=2时
∇w=i=1∑Nsgn(wTxi)∣∣∣wTxi∣∣∣p−1xi=i=1∑NxixiTw
∇w⊥=(Id−wwT)i=1∑Nsgn(wTxi)∣∣∣wTxi∣∣∣p−1xi=(Id−wwT)XXTw
因此优化问题可以通过协方差矩阵的特征值分解解决。而梯度正交向量有如下性质:
∇w⊥=0⟺∇w=XXTw
拉格朗日乘子法
约束优化问题转化为如下
L(w,λ)=Fp(w)+λ(wTw−1)
令拉格朗日函数导数为0可得最优解的必要性
dwdL(w,λ)=∇w+λw=0
可得w与梯度∇w平行,又∥w∥2=1,因此可对w直接更新
w←∥∇w∥2∇w
通常情况下,这种令导数为零方法取到的不仅是最大值,也有可能是最小值。因此在ℓp-PCA里,对p≥1,由Fp的凸性可得该迭代下的目标函数非减。
Fp(wk+1)≥Fp(wk)+∇wT(wk+1−wk)≥Fp(wk)
第二个不等号是因为∥wk+1∥2=∥wk∥2=1且wk+1平行于∇w,∇wTwk+1=1。

基于Lagrangian乘子法的PCA-Lp算法
求解算法(m>1)
贪婪算法(近似求解)

非贪婪解
对目标函数求梯度
∇W=dWdFp(W)=[∇w1,…,∇wm]
对应的拉格朗日函数为
L(W,Γm)=Fp(W)+tr(ΓmT(WTW−Im))
同样的,设导数为0,即
dWdL(W,Γm)=∇W+2WΓm=0
迭代不能再是简单的赋值,需满足正交约束,因此考虑如下优化问题
W∗=argQmaxtr(QT∇W)s.t.QTQ=Im
设∇W的SVD分解为∇W=UΛVT,记Z=VTQTU,得ZZT=Id,zii≤1。因此
tr(QT∇W)=tr(QTUΛVT)=tr(ΛVTQTU)=tr(ΛZ)=i∑λiizii≤i∑λii
取等号时当且仅当zii=1,此时Z=[Im∣0],最优解
W∗=UZTVT=U[Im∣0]TVT

参考文献